人工智能资讯 第2页
聚合当前分类下的最新内容,按时间顺序查看第 2 页精选文章。

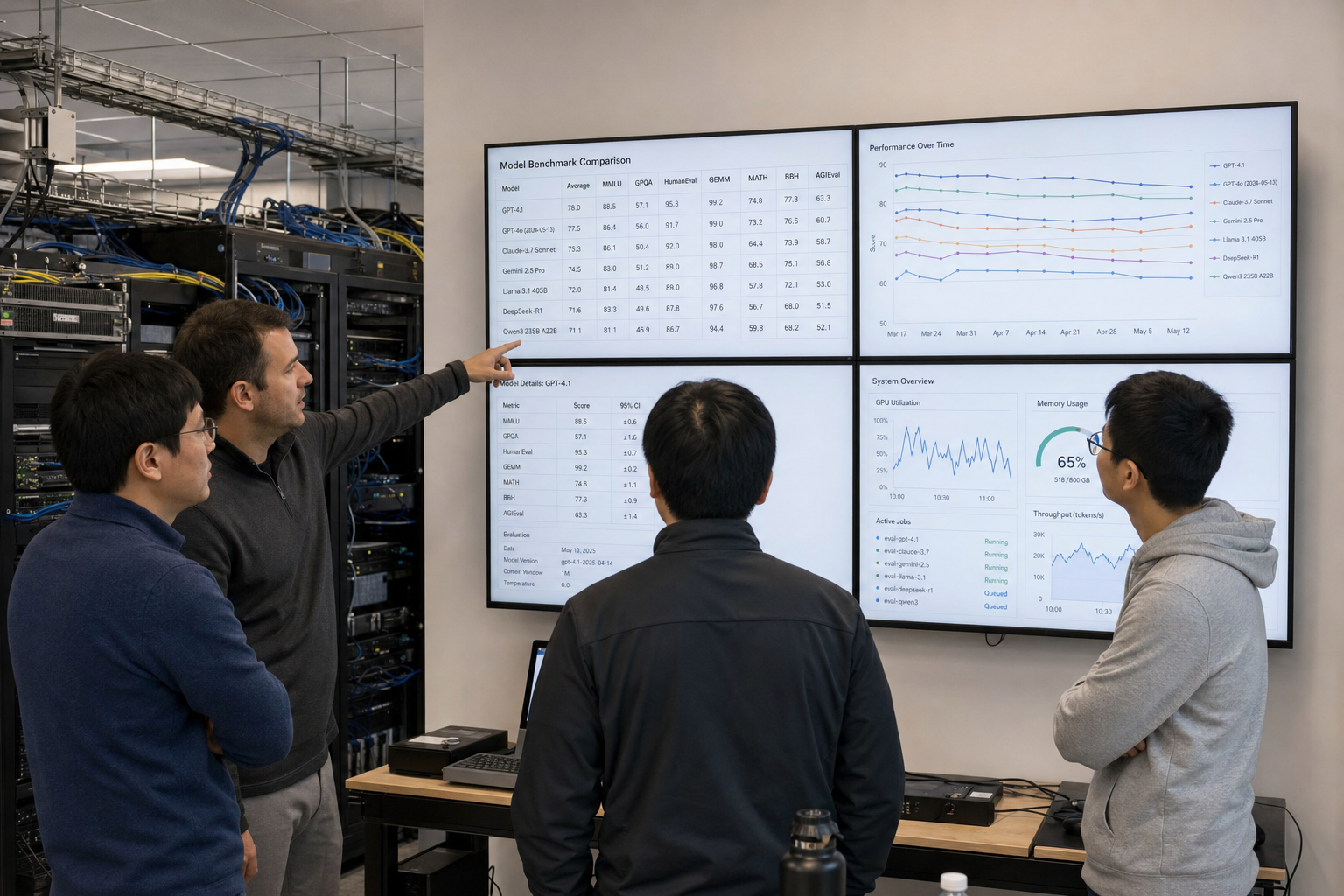
AI 让人反感的,不是能力,而是一路不问同意
一位原本只把生成式 AI 当玩具的博主,梳理了自己从中立到厌恶 AI 的过程。真正的转折不是模型变强,而是行业用 FOMO、平台入口和条款改写,把用户与创作者的拒绝权越推越窄。最该观察的变量不是 AI 还能多聪明,而是训练数据、产品植入和创作者授权能不能补上真正的 opt-out。

GPT-5.5 Instant开放给免费用户:OpenAI想证明健康回答更可靠,但不是让AI看病
OpenAI称,GPT-5.5 Instant提升了ChatGPT在健康与保健问题上的回答能力,免费用户也可使用,但有额度限制。关键不在于AI能否替代医生,而在于OpenAI开始用医生评审、HealthBench和线上监测来证明回答更可靠。普通用户可以把它当作就医前的信息整理工具,医疗科技团队则要更认真看评测方法和责任边界。

Karamo Brown 把自己做进健康 App:AI 分身卖的是亲密感,风险也在这里
Karamo Brown 推出健康应用 Kē,月费 14.99 美元,功能包括健身、饮食、冥想、社群和由 Delphi 驱动的 AI Karamo。真正关键的不是明星又做 App,而是名人信任被做成可订阅的 AI 陪伴。用户该用它做轻量健康管理,但别把情绪、戒酒、关系困境的底牌全交给一个数字分身。

General Intuition洽谈3亿美元融资:游戏视频会是智能体的好矿,还是新叙事的燃料?
TechCrunch称,General Intuition正洽谈约3亿美元融资,估值略高于20亿美元;交易尚未完成,金额和投资方都要打折看。真正值钱的不是“又一家AI公司涨估值”,而是Medal留下的第一人称游戏视频数据:每年约20亿条视频、1000万月活用户。我的判断很简单:游戏视频是训练时空推理的好矿,但它还不是现实智能体的通行证。
LoRA 仍然能打,但别再把它当微调默认答案
Hugging Face 的 PEFT 基准没有宣判 LoRA 退场,反而说明它仍在不少任务里很强。真正该警惕的是默认路径:普通 LoRA 在部分指标上已经不占优,OFT、BEFT、Lily 等方法值得被放进同一轮自测。对工程团队来说,选择微调方法不该只看分数,还要看显存、checkpoint、部署框架和排障成本。

OpenAI 用 o3 复盘儿童罕见病旧案:4.8% 不高,但击中了医疗 AI 的真入口
波士顿儿童医院、哈佛与 OpenAI 用 o3 Deep Research 复盘 376 个长期未解的儿童罕见病相关病例,经专家和临床流程确认后新增 18 个诊断,额外诊断率 4.8%。模型没有直接下诊断,只提供候选线索和证据链;真正的价值在于把罕见病诊断里最慢、最容易漏掉的知识更新,变成可复盘的流程。接下来该看的不是宣传口径,而是它能否在前瞻性临床流程里降低时间、成本和误报负担。

Hermes 开放 OpenClaw 迁移:方便是真的,控制权也是真的
Nous Research 的 Hermes Agent 提供 `hermes claw migrate` 迁移指南,可把 OpenClaw 及旧版 Clawdbot/Moltbot 的配置、记忆、技能、模型供应商、MCP、TTS 和消息平台配置迁入 Hermes。 它不是无损搬家:密钥默认不迁,必须显式加 `--migrate-secrets`;部分 OpenClaw 能力只能归档,后续要人工重建。 这件事的关键不在“多接几个模型”,而在 Agent 工具开始争夺用户的长期记忆、技能和执行入口。

微软研究员用《帝国时代2》山羊拆穿 AI 意识叙事
微软 AI 研究员 Adrian de Wynter 用《帝国时代 II》的场景编辑器搭出 NAND 门和 1-bit 感知机,让山羊在草和桥之间传递 bit,故意把 LLM 拟人化推到荒诞处。它没有证明 LLM 一定无意识,只是在提醒:聊天界面、营销话术和研究假设,正在把统计机器包装成人格对象。对用户、产品经理和研究者来说,接下来最该盯的不是模型会不会“像人”,而是产品和论文有没有把“像人”偷偷当成前提。

Claude Fable 5 被紧急下线:美国 AI 监管迈出一步,也露出乱象
Anthropic 发布 Claude Fable 5 不到一周,美国政府因疑似越狱风险对 Fable 5 及底层 Mythos 5 实施出口管制,Anthropic 随后将两款模型全面下线。真正重要的不是一次潜在漏洞,而是美国正在用怎样的程序决定“哪个 AI 太危险”:目前看,它更像临时政治干预,而不是稳定监管框架。

Adobe 把 Firefly 接进 Premiere:专业软件不再只拼按钮
Adobe 正在把 Firefly AI 助手扩展到 Premiere、Illustrator、InDesign 和 Frame.io,重点不是多几个生成按钮,而是把素材整理、图层维护、品牌资产复用这些脏活交给 AI。Elements 和 Projects 仍是 private beta,别把它理解成全 Creative Cloud 通用 AI 代理已经落地。真正受影响的是剪辑师、设计师和品牌内容团队:低价值操作会被压缩,专业判断和资产管理能力会变得更贵。
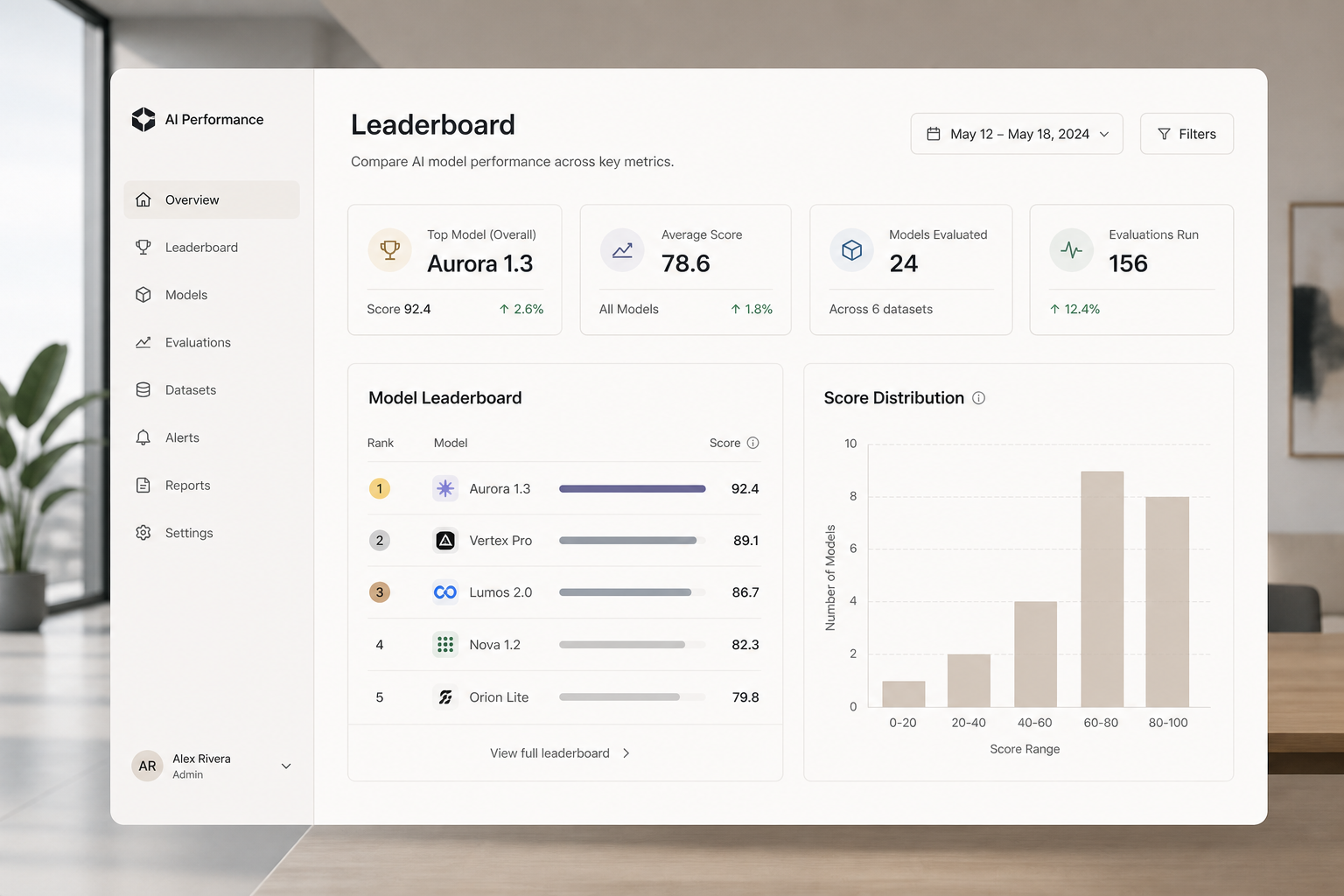
Salesforce内部AI排行榜曝光:徽章不算绩效,但压力已经上桌
404 Media披露,Salesforce内部用排行榜追踪团队AI工具使用率和培训徽章进度,还能点开查看谁没有拿到徽章。公司称榜单不为竞争设计,也不关联绩效,但员工担心AI使用正在变成隐性考核。真正该看的不是有没有徽章,而是企业把AI落地量化之后,数据会不会被经理、团队和员工自己当成绩效信号。

Hugging Face 的 Agent 基准:软件库开始争夺机器执行路径
Hugging Face 用 transformers 做案例,发布了一套面向 agent 使用场景的基准方法,看的不只是答案,还看轮次、时间、token、错误和工具采用路径。 这件事的重点不是给开放模型排座次,而是提醒软件库维护者:API、文档、CLI 和示例,已经开始影响 agent 的成本、速度和成功率。 对用 coding agent 的团队来说,真正该看的不是“能不能做对”,而是“它靠什么路径做对”。绕路成功,在规模化使用里就是账单和风险。
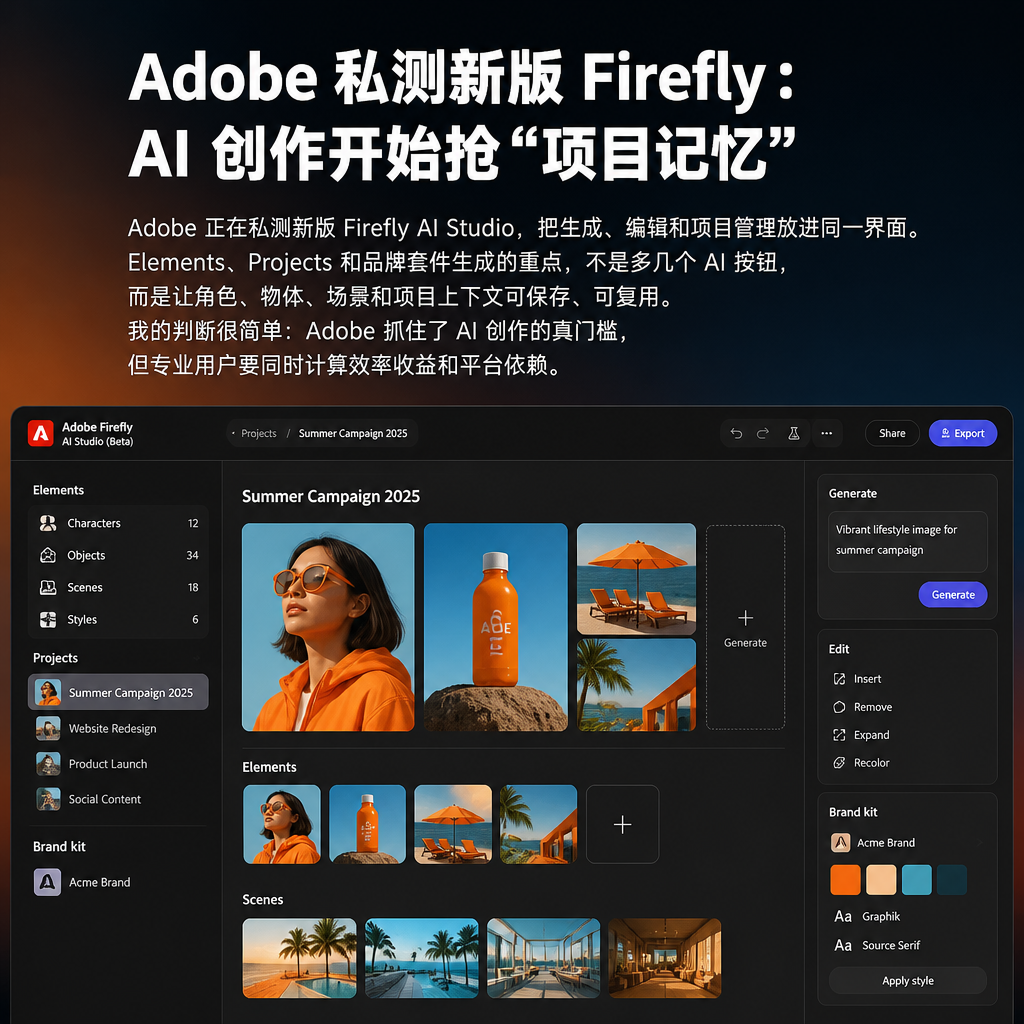
Adobe 私测新版 Firefly:AI 创作开始抢“项目记忆”
Adobe 正在私测新版 Firefly AI Studio,把生成、编辑和项目管理放进同一界面。Elements、Projects 和品牌套件生成的重点,不是多几个 AI 按钮,而是让角色、物体、场景和项目上下文可保存、可复用。我的判断很简单:Adobe 抓住了 AI 创作的真门槛,但专业用户要同时计算效率收益和平台依赖。
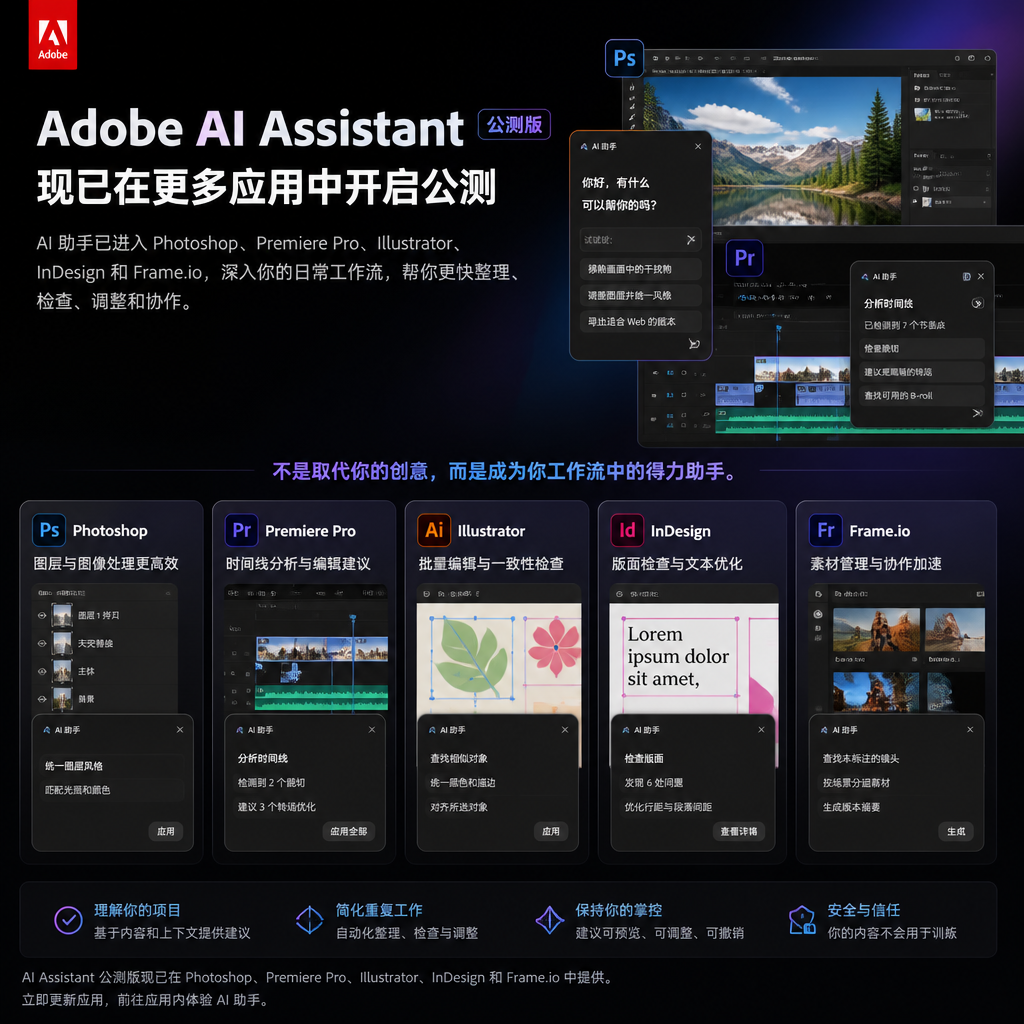
Adobe把AI助手放进Photoshop和Premiere,重点不是生成图片
Adobe在Photoshop、Premiere、Illustrator、InDesign和Frame.io中开启AI Assistant公测,不是全量正式发布。更关键的变化是,AI开始进入素材整理、时间线、图层、版面检查和批量修改这些日常工作流。对设计师和剪辑师来说,它更像应用内助理,不是替人交付完整作品的自动创作系统。

Waymo 召回近 4000 辆 robotaxi:高速施工区把自动驾驶逼到真问题前
Waymo 因至少 13 起 robotaxi 闯入封闭高速施工区事件,发起近 4000 辆车的自愿软件召回,并从 5 月 19 日起暂停所有高速运营。地面道路服务仍在继续,目前没有材料显示造成人员伤亡。 这件事的关键不是“Waymo 不安全”,而是自动驾驶规模化后,施工区这类临时、高速、高风险场景开始撞上系统边界、运营边界和监管责任。

Pixi 把 AR 角色塞进 iMessage:比表情包更进一步,但还不是社交新入口
Pixi 在 App Store 上线 iOS 应用,用户可通过 iMessage 发送由端侧 AI 驱动的互动 AR 角色,收件人无需安装应用即可查看。它的看点不是“AR 消息”这个概念本身,而是试图把 AR 从滤镜和镜头玩法推进到聊天里的互动表达。真正的难题在于:这些角色能否持续好玩、足够轻量,并让品牌和创作者愿意投入。

AI帮MAME啃旧Mac:找到了硬骨头,但方向盘还在人手里
MAME 开发者用 Claude Code 和 GPT/Codex 辅助调试 Power Macintosh 与 Pippin,推进了启动声、logo、找盘界面和 System 7.5.x 引导等问题。AI 的价值不在“自动写完代码”,而在放大专家的逆向、日志和调试搜索能力。边界也很硬:线索可以由 AI 提供,判断、修复和长期维护仍由人承担。

本地 Qwen 不是低配 Opus:跑分、账本和真实边界
Alex Ellis 的判断很直接:本地 Qwen 27B/35-A3B 不是 Claude Opus 的低配版,而是另一种工具。 它的价值在固定成本、数据不出门和降低供应商依赖;短板在长上下文、工具调用和无人值守任务。 对小团队和企业技术负责人来说,正确动作不是立刻替换 Claude,而是把本地模型放进支持、检索和小任务流程里试运行。

Google Docs 里 Gemini 提示太扰人?真正能关掉的是这些入口
Google Docs 部分用户在写作时遇到“write with Gemini”等 AI 提示框,当前可通过 Docs 顶部 Gemini 菜单关闭底部提示栏,也可到 Gmail 里管理 Workspace 智能功能。关键判断是:这不是 Google 提供了“一键关闭所有 AI”的总开关,而是给被打断的写作者减少入口和弹窗的几条实用路径。

GLM-5.2 开放权重:分数很强,账单还要重算
Z.ai 已在 6 月 16 日开放 GLM-5.2 完整权重,MIT 许可,753B 参数,1M token 上下文,当前在多个开放权重模型评测中站到前排。它的分水岭不只是分数高,而是用开放权重、低 API 单价和编码能力继续挤压闭源模型。问题也很硬:输出 token 消耗高,部署门槛重,能力并不均匀。

早看中 Facebook 的投资人:AI 最大赢家,可能不卖 AI
Chi-Hua Chien 在 TechCrunch 访谈中判断,AI 模型层正在商品化,消费级 AI 已经出现降价竞争。真正的大价值可能不在“卖 AI”,而在用 AI 改造娱乐、医疗、金融和线下体验的应用公司。对创业者和投资人来说,问题不再只是模型多强,而是谁掌握场景、分发、留存和信任。