人工智能资讯 第28页
聚合当前分类下的最新内容,按时间顺序查看第 28 页精选文章。

George Hotz 质疑 AI agent 写代码:产量上去了,质量判断更难了
George Hotz 在《The Eternal Sloptember》中批评 AI agent 大规模进入软件开发,核心担心不是它写得慢,而是它写出“看起来能用”的低质代码。更值得警惕的是,团队可能把代码产量误当工程能力,把短期 demo 误当可维护系统。AI 仍适合搜索、原型和辅助探索,但目前还不能等同于合格软件工程师。
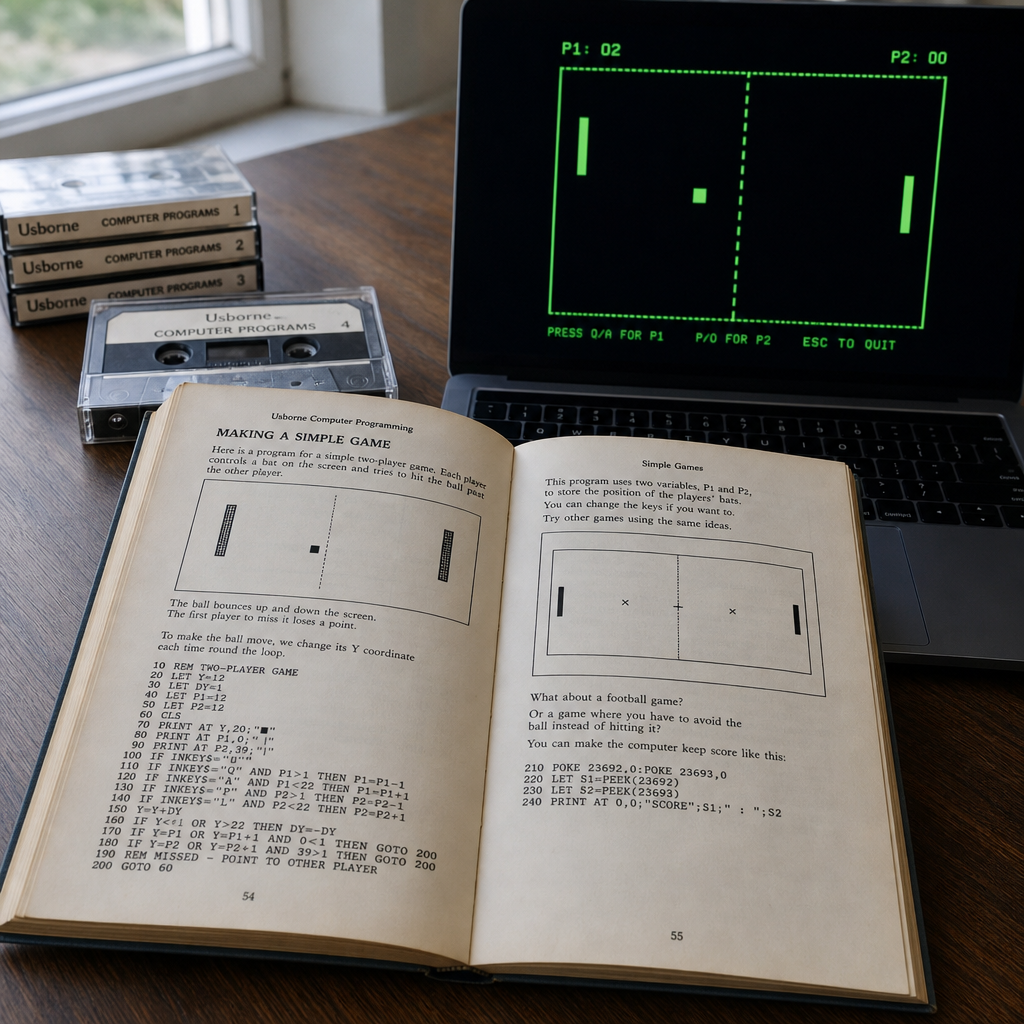
Claude把1983年纸上游戏搬上网页,关键不是怀旧
Simon Willison 把 Usborne 免费开放的 1980 年代计算机书 PDF 输入 Claude,让它将《Creepy Computer Games》里的 Mad House 做成可交互的 JS/HTML 网页版。这个案例的重点不是 Usborne 发布了新游戏,而是 AI 编程工具正在降低旧纸质代码转译为现代网页的门槛。对开发者和复古计算机爱好者来说,下一步要看来源标注、校验过程和还原边界。

AI 改写的 GitHub issue,正在把开源维护者拖进雾里
Armin Ronacher 批评的不是 AI 编程,而是开源项目里越来越多被 AI 改写的 GitHub issue:真实问题还在,但外面包了一层自信、错误、难验证的推断。维护者需要的是命令、预期、实际结果和准确日志,不是模型替用户编出来的根因、复现和修复建议。更大的问题是成本转移:开发者省了表达,开源维护者多了排雷。

亚马逊收购后的 Bee 手环:会议省事了,生活边界也变薄了
TechCrunch 试用了亚马逊收购后的 Bee AI 手环:用户开启录音后,它能记录对话、转写、生成摘要,并接入日历提醒。 它在商务电话和会议纪要里确实省事,但转写、说话人识别和遗漏问题还会削弱信任。 真正的分水岭不是手环好不好玩,而是用户愿不愿意把“默认不被记录”的日常交给平台入口。

AI 写后端的分水岭:功能会跑不够,约束守住才算数
一篇新论文系统评估 LLM agents 生成多文件后端代码时的约束遵守能力,提出了 constraint decay:架构、数据库、ORM 等结构要求越多,表现越容易衰减。论文同时看端到端行为测试和静态验证器,避免只奖励“功能跑通”。对后端团队和 AI coding 产品来说,真正的考题不是 CRUD demo,而是 agent 能不能稳定服从工程秩序。

Nuro转向Robotaxi:靠Uber和Lucid做“第二名”,难点不在晚到
Nuro在2024年从自动配送转向Robotaxi,计划与Uber、Lucid合作,今年晚些时候先在旧金山启动服务,目前只拿到启动所需许可中的第一项。它押注“第二行动者优势”,可以少踩Waymo踩过的坑,但不能跳过许可、乘客运营和真实道路磨损。对行业观察者和出行、车企从业者来说,关键不是Nuro会不会讲故事,而是这套三方拆分模式能不能跑成稳定服务。

法拉利把 AI 塞进粉丝 App,想抢回的不是流量,是关系
法拉利与 IBM 改造官方粉丝 App,新增意大利语、AI 赛事摘要、问答助手、预测游戏和幕后内容。IBM 称接入后比赛周末 App engagement 增长 62%,但这只能说明互动提升,不能外推成收入或用户规模增长。更关键的变化是:法拉利正在把粉丝关系从社交平台和 F1 官方平台手里往回收。

深度学习加速别先堆技巧:真正要先找出 GPU 卡在哪里
Horace He 的文章把深度学习性能优化拉回一个基本判断:先确认瓶颈是计算、显存带宽还是框架调度开销,再选择工具。对工程团队来说,真正有价值的不是记住某个 PyTorch 小技巧,而是建立一套能解释 achieved FLOPS、带宽利用率和算子融合收益的诊断方法。

Google Omni Flash:AI 视频的分水岭,是骗过熟人第一眼
Google 在 I/O 2026 后推出 Gemini Omni 系列首个视频模型 Omni Flash,并接入 Flow,重点能力是视频生成和编辑。它相较 Veo 更听提示、更能保持角色一致性,也支持上传视频配合文本改片。真正该警惕的不是它能不能拍大片,而是低门槛真实视频正在把深伪变成消费级工具。

Peec AI 年化收入破 1000 万美元:欧洲 AI 创业叙事正在从估值回到收入
柏林创业公司 Peec AI 的年化收入已超过 1000 万美元,较半年前披露的 400 万美元以上明显翻倍。这个数字不能等同于全年已确认收入或利润,但它提供了一个清晰样本:欧洲 AI 创业公司正在用 ARR 增长替代单纯估值故事。对品牌营销团队和投资人来说,AI 搜索可见性正在从概念预算进入工具采购讨论。

AI 还没回本:1.4 万亿美元砸下去,谁先赚到了钱?
一个追踪前沿 AI 公司盈亏的网站估算,截至 2026 年 5 月,AI 行业累计投入约 1.4 万亿美元,累计收入约 7180 亿美元。数字不是审计财报,口径也混杂,但方向很清楚:大模型公司和云厂商在承担前置成本,英伟达先拿走了最确定的收入。判断 AI 不能只问有没有用,更要问利润被谁捕获、亏损由谁扛。

NVIDIA 发 Nemotron Diffusion:别只看快几倍,刀口在推理成本
NVIDIA 在 Hugging Face 发布 Nemotron-Labs Diffusion 系列,覆盖 3B、8B、14B 文本模型和 8B 视觉语言模型;文本模型支持自回归、扩散、自推测三种生成模式切换。它的重点不是宣布扩散语言模型取代自回归,而是把推理加速做成一个可部署、可回退、可验证的工程选项。对低延迟应用、推理服务商和小 batch 企业场景来说,真正要算的是端到端延迟、硬件利用率和迁移风险。

犹他县城拦 AI 数据中心:算力项目的账,不能绕过社区
犹他州 Box Elder 县居民组织 B.E.A.R. 正推动 Box Elder Referendum 26-11 和 26-12,目标是阻止 Stratos-MIDA AI 数据中心项目继续推进。争议集中在三件事:税收优惠是否公平、干旱地区新增工业用水压力、县政府或 MIDA 决策是否缺少公开审查。它不是反 AI,而是在问一个更硬的问题:算力扩张落到地方后,谁获利,谁买单,谁有决定权。

别把 AI 原文甩给同事:协作里的新失礼
《Don't just paste the AI at me》批评的不是用 AI,而是在对话、协作和评审中直接粘贴未经处理的模型回复。 对方找你,是要你的经验、判断和语境;把 AI 初稿原样转发,等于把思考外包给模型,再把成本推给别人。 更合理的做法是:读完、核对、删改、加入自己的判断;必须引用模型时,标清来源,并说明它为什么可信或有用。

Virgin Atlantic 用 Codex 赶圣诞上线:AI 编程撞上的不是代码,是交付链条
Virgin Atlantic 用 Codex 辅助新版移动 App 交付:圣诞期间 beta,数周后生产上线,接近完整单元测试覆盖,上线时没有 P1 ticket。 这不是“AI 独立写完 App”的故事,更像一次企业交付压力测试:编码变快后,测试、后端排期、数据治理和审批流程会立刻变成新瓶颈。 对技术管理者和开发者来说,重点不是急着买工具,而是把 AI 放进测试、重构、代码审查和发布责任链里。

Models.dev 开源:AI 模型太多以后,开发者需要一张明账
Models.dev 在 GitHub 开源了一个社区维护的 AI 模型规格数据库,用 TOML 记录价格、上下文、模态、工具调用、结构化输出等字段,并通过 https://models.dev/api.json 输出。它的价值不在做模型排行榜,而在给多模型应用提供一层可机器读取、可协作更新的基础账本。真正要观察的是:数据能否跟上厂商定价和接口变化,能否被更多工具链消费。
Grok 在美国政府记录里只出现 3 次,xAI 的估值故事缺一张硬牌
路透梳理美国政府 400 多个具名 AI 使用案例,Grok/xAI 只出现 3 次,OpenAI 模型超过 230 次。这个数据不能证明 xAI 失败,因为口径不覆盖全部政府 AI 使用,也不充分覆盖情报机构和五角大楼。但它至少说明:马斯克能制造声量,Grok 还没证明自己能大规模获得机构信任。

Google AI Overviews 把“ignore”当指令:不是搜索坏了,是边界串线了
Google 搜索里的 AI Overviews 在部分查询中出现异常:搜索“disregard”“ignore”“skip”等词时,它没有生成搜索摘要,而是回了“Got it”“No problem”“Message received”这类聊天式确认。The Verge 多名同事复现过,但结果会变化,不能扩大成所有用户、所有地区都受影响。我的判断是,这更像短期 bug,不是 Google 搜索整体失灵;但它暴露了 AI 搜索最关键的一道边界:用户是在查词,还是在下指令。

Google 的显示版 AI 眼镜快能用了,但现在还不是掏钱的时候
Google 在 I/O 展示的是带单眼显示屏的 Android XR AI 眼镜原型,不是今年秋季先发的 audio-only 眼镜;它能把 Gemini、翻译、导航、拍照、识物和小组件叠到视野里。最有价值的场景不是 AI 问答,而是实时字幕翻译和免掏手机导航。显示、延迟、隐私、生态接入和日常佩戴还没过关,用户该观望,开发者可以先盯 Android XR 的接口和测试节奏。

Dharma-AI称3B OCR模型跑赢商业API:企业选AI不能只看“大模型招牌”
Dharma-AI在Hugging Face文章中称,其面向巴西葡语OCR的3B专门化模型,在自研DharmaOCR基准上以0.911分领先Claude Opus 4.6、Gemini 3.1 Pro和GPT-5.4。这个结果的价值不在于证明“小模型全面胜利”,而在于提醒企业采购AI时,模型训练历史和任务分布匹配度可能比参数规模更关键。

《真相的未来》被 AI 塞进假引语,问题比作者翻车更麻烦
Steven Rosenbaum 在写《The Future of Truth》时用 ChatGPT、Claude 等 AI 做研究,纽约时报在 285 条外部引文中发现至少 6 条有问题,其中 3 条属于无明显来源的“合成引语”。这件事的反讽不只在书名,而在 AI 研究笔记已经能混进出版、新闻和学术流程。对内容行业来说,接下来要盯的不是作者道歉多诚恳,而是引文审计和工作流能不能把假材料挡在稿件外。